Dataset
Why Would You Use Datasets?
The dataset entity is one the most important entities in the metadata model. They represent collections of data that are typically represented as Tables or Views in a database (e.g. BigQuery, Snowflake, Redshift etc.), Streams in a stream-processing environment (Kafka, Pulsar etc.), bundles of data found as Files or Folders in data lake systems (S3, ADLS, etc.). For more information about datasets, refer to Dataset.
Goal Of This Guide
This guide will show you how to
- Create: create a dataset with three columns.
- Delete: delete a dataset.
Prerequisites
For this tutorial, you need to deploy DataHub Quickstart and ingest sample data. For detailed steps, please refer to Datahub Quickstart Guide.
Create Dataset
- GraphQL
- Java
- Python
🚫 Creating a dataset via
graphqlis currently not supported. Please check out API feature comparison table for more information.
# Inlined from /metadata-integration/java/examples/src/main/java/io/datahubproject/examples/DatasetAdd.java
package io.datahubproject.examples;
import com.linkedin.common.AuditStamp;
import com.linkedin.common.urn.CorpuserUrn;
import com.linkedin.common.urn.DataPlatformUrn;
import com.linkedin.common.urn.DatasetUrn;
import com.linkedin.common.urn.UrnUtils;
import com.linkedin.schema.DateType;
import com.linkedin.schema.OtherSchema;
import com.linkedin.schema.SchemaField;
import com.linkedin.schema.SchemaFieldArray;
import com.linkedin.schema.SchemaFieldDataType;
import com.linkedin.schema.SchemaMetadata;
import com.linkedin.schema.StringType;
import datahub.client.MetadataWriteResponse;
import datahub.client.rest.RestEmitter;
import datahub.event.MetadataChangeProposalWrapper;
import java.io.IOException;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class DatasetAdd {
private DatasetAdd() {
}
public static void main(String[] args) throws IOException, ExecutionException, InterruptedException {
DatasetUrn datasetUrn = UrnUtils.toDatasetUrn("hive", "fct_users_deleted", "PROD");
CorpuserUrn userUrn = new CorpuserUrn("ingestion");
AuditStamp lastModified = new AuditStamp().setTime(1640692800000L).setActor(userUrn);
SchemaMetadata schemaMetadata = new SchemaMetadata()
.setSchemaName("customer")
.setPlatform(new DataPlatformUrn("hive"))
.setVersion(0L)
.setHash("")
.setPlatformSchema(SchemaMetadata.PlatformSchema.create(new OtherSchema().setRawSchema("__insert raw schema here__")))
.setLastModified(lastModified);
SchemaFieldArray fields = new SchemaFieldArray();
SchemaField field1 = new SchemaField()
.setFieldPath("address.zipcode")
.setType(new SchemaFieldDataType().setType(SchemaFieldDataType.Type.create(new StringType())))
.setNativeDataType("VARCHAR(50)")
.setDescription("This is the zipcode of the address. Specified using extended form and limited to addresses in the United States")
.setLastModified(lastModified);
fields.add(field1);
SchemaField field2 = new SchemaField().setFieldPath("address.street")
.setType(new SchemaFieldDataType().setType(SchemaFieldDataType.Type.create(new StringType())))
.setNativeDataType("VARCHAR(100)")
.setDescription("Street corresponding to the address")
.setLastModified(lastModified);
fields.add(field2);
SchemaField field3 = new SchemaField().setFieldPath("last_sold_date")
.setType(new SchemaFieldDataType().setType(SchemaFieldDataType.Type.create(new DateType())))
.setNativeDataType("Date")
.setDescription("Date of the last sale date for this property")
.setLastModified(lastModified);
fields.add(field3);
schemaMetadata.setFields(fields);
MetadataChangeProposalWrapper mcpw = MetadataChangeProposalWrapper.builder()
.entityType("dataset")
.entityUrn(datasetUrn)
.upsert()
.aspect(schemaMetadata)
.build();
String token = "";
RestEmitter emitter = RestEmitter.create(
b -> b.server("http://localhost:8080")
.token(token)
);
Future<MetadataWriteResponse> response = emitter.emit(mcpw, null);
System.out.println(response.get().getResponseContent());
}
}
# Inlined from /metadata-ingestion/examples/library/dataset_schema.py
# Imports for urn construction utility methods
from datahub.emitter.mce_builder import make_data_platform_urn, make_dataset_urn
from datahub.emitter.mcp import MetadataChangeProposalWrapper
from datahub.emitter.rest_emitter import DatahubRestEmitter
# Imports for metadata model classes
from datahub.metadata.schema_classes import (
AuditStampClass,
DateTypeClass,
OtherSchemaClass,
SchemaFieldClass,
SchemaFieldDataTypeClass,
SchemaMetadataClass,
StringTypeClass,
)
event: MetadataChangeProposalWrapper = MetadataChangeProposalWrapper(
entityUrn=make_dataset_urn(platform="hive", name="realestate_db.sales", env="PROD"),
aspect=SchemaMetadataClass(
schemaName="customer", # not used
platform=make_data_platform_urn("hive"), # important <- platform must be an urn
version=0, # when the source system has a notion of versioning of schemas, insert this in, otherwise leave as 0
hash="", # when the source system has a notion of unique schemas identified via hash, include a hash, else leave it as empty string
platformSchema=OtherSchemaClass(rawSchema="__insert raw schema here__"),
lastModified=AuditStampClass(
time=1640692800000, actor="urn:li:corpuser:ingestion"
),
fields=[
SchemaFieldClass(
fieldPath="address.zipcode",
type=SchemaFieldDataTypeClass(type=StringTypeClass()),
nativeDataType="VARCHAR(50)", # use this to provide the type of the field in the source system's vernacular
description="This is the zipcode of the address. Specified using extended form and limited to addresses in the United States",
lastModified=AuditStampClass(
time=1640692800000, actor="urn:li:corpuser:ingestion"
),
),
SchemaFieldClass(
fieldPath="address.street",
type=SchemaFieldDataTypeClass(type=StringTypeClass()),
nativeDataType="VARCHAR(100)",
description="Street corresponding to the address",
lastModified=AuditStampClass(
time=1640692800000, actor="urn:li:corpuser:ingestion"
),
),
SchemaFieldClass(
fieldPath="last_sold_date",
type=SchemaFieldDataTypeClass(type=DateTypeClass()),
nativeDataType="Date",
description="Date of the last sale date for this property",
created=AuditStampClass(
time=1640692800000, actor="urn:li:corpuser:ingestion"
),
lastModified=AuditStampClass(
time=1640692800000, actor="urn:li:corpuser:ingestion"
),
),
],
),
)
# Create rest emitter
rest_emitter = DatahubRestEmitter(gms_server="http://localhost:8080")
rest_emitter.emit(event)
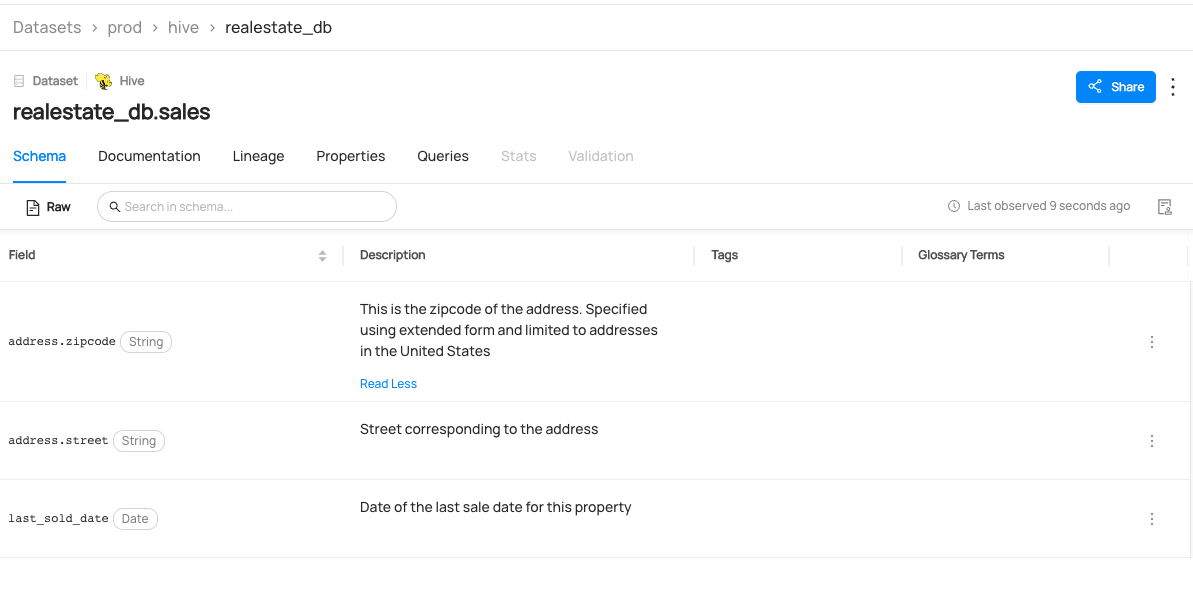
Expected Outcomes of Creating Dataset
You can now see realestate_db.sales dataset has been created.
Delete Dataset
You may want to delete a dataset if it is no longer needed, contains incorrect or sensitive information, or if it was created for testing purposes and is no longer necessary in production. It is possible to delete entities via CLI, but a programmatic approach is necessary for scalability.
There are two methods of deletion: soft delete and hard delete. Soft delete sets the Status aspect of the entity to Removed, which hides the entity and all its aspects from being returned by the UI. Hard delete physically deletes all rows for all aspects of the entity.
For more information about soft delete and hard delete, please refer to Removing Metadata from DataHub.
- GraphQL
- Curl
- Python
🚫 Hard delete with
graphqlis currently not supported. Please check out API feature comparison table for more information.
mutation batchUpdateSoftDeleted {
batchUpdateSoftDeleted(input:
{ urns: ["urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_deleted,PROD)"],
deleted: true })
}
If you see the following response, the operation was successful:
{
"data": {
"batchUpdateSoftDeleted": true
},
"extensions": {}
}
curl --location --request POST 'http://localhost:8080/api/graphql' \
--header 'Authorization: Bearer <my-access-token>' \
--header 'Content-Type: application/json' \
--data-raw '{ "query": "mutation batchUpdateSoftDeleted { batchUpdateSoftDeleted(input: { deleted: true, urns: [\"urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_deleted,PROD)\"] }) }", "variables":{}}'
Expected Response:
{ "data": { "batchUpdateSoftDeleted": true }, "extensions": {} }
# Inlined from /metadata-ingestion/examples/library/delete_dataset.py
import logging
from datahub.emitter.mce_builder import make_dataset_urn
from datahub.ingestion.graph.client import DatahubClientConfig, DataHubGraph
log = logging.getLogger(__name__)
logging.basicConfig(level=logging.INFO)
graph = DataHubGraph(
config=DatahubClientConfig(
server="http://localhost:8080",
)
)
dataset_urn = make_dataset_urn(name="fct_users_created", platform="hive")
# Soft-delete the dataset.
graph.delete_entity(urn=dataset_urn, hard=False)
log.info(f"Deleted dataset {dataset_urn}")
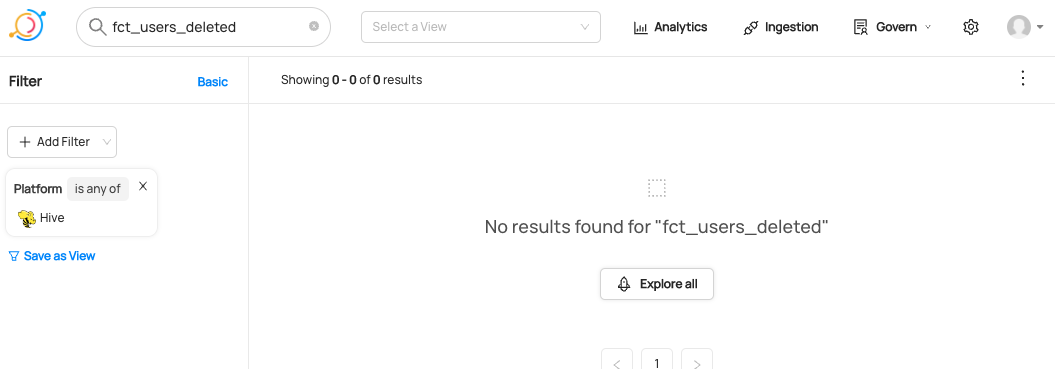
Expected Outcomes of Deleting Dataset
The dataset fct_users_deleted has now been deleted, so if you search for a hive dataset named fct_users_delete, you will no longer be able to see it.